Viens no visizplatītākajiem pieņēmumiem par mākslīgā intelekta attīstību ir tāds, ka labāki modeļi nozīmē precīzākus modeļus. Vairāk parametru, vairāk apmācības datu, sarežģītāka arhitektūra — un mazāk kļūdu. Realitāte ir traucējoši sarežģītāka. Jau 2025. gadā parādījās arvien vairāk pierādījumu, ka daži no spējīgākajiem AI modeļiem halucinē biežāk nekā to priekšgājēji, un šī tendence turpinās arī 2026. gadā. Šis paradokss nav nejaušs — tam ir strukturāli cēloņi, un to izpratne kļūst svarīgāka ikvienam, kurš izmanto AI savā ikdienas darbā vai dzīvē.
Kas ir AI halucinācija
AI halucinācija ir parādība, kad valodas modelis ģenerē faktiski nepareizu, bet pārliecinoši izskatīgu informāciju. Modelis "izdomā" faktus, citātus, zinātniskus rakstus vai statistiku, kas neeksistē — un to dara ar pilnīgu pārliecību, bez jebkādas brīdinājuma zīmes.
Svarīgi saprast, ka halucinācija nav kļūda klasiskā programmēšanas izpratnē. Tā nav situācija, kad kods nedarbojas. Tā ir situācija, kad modelis darbojas tieši tā, kā tas ir apmācīts — ģenerēt visticamāko atbildi, pamatojoties uz statistiskajiem modeļiem, nevis uz faktu pārbaudi. Modelis nezina, ka kļūdās — tas vienkārši turpina ģenerēt tekstu, kas statistiski šķiet pareizs. Problēma nav darbības traucējums; problēma ir pašā arhitektūrā.
Skaitļi, kas maina priekšstatu
NewsGuard 2025. gada ziņojums konstatēja, ka labāko AI tērzētājprogrammu radīto nepatieso apgalvojumu skaits, atbildot uz jautājumiem par aktualitātēm, gandrīz divkāršojās viena gada laikā — no 18% 2024. gada augustā līdz 35% 2025. gada augustā.
Vēl skaudrāki ir OpenAI paša tehniskie dati. Modelis o3 halucinēja 33% gadījumu, savukārt o4-mini — 48%, salīdzinot ar tikai 16% iepriekšējam o1 modelim. Vectara halucināciju mērījumu līderpanelī arī DeepSeek-R1 parādīja ievērojami augstāku halucināciju līmeni nekā tā priekšgājējs, lai gan tas tika projektēts ar uzlabotām spriešanas spējām.
Tajā pašā laikā pastāv pretēja tendence: uz konkrētiem, pārbaudāmiem uzdevumiem — tekstu apkopošana, dokumentu analīze, kur modelis var balstīties uz avotu — halucināciju skaits samazinās. Vadošie modeļi šajos uzdevumos sasniedza halucināciju līmeni zem 1%. Atšķirība nav starp labiem un sliktiem modeļiem — tā ir starp dažādu uzdevumu veidiem.
Kāpēc gudrāki modeļi halucinē vairāk
Paradoksa izskaidrojums sakņojas tajā, ko nozīmē "gudrāks" AI kontekstā. Jaunākā paaudze, tā sauktie "reasoning models", ir projektēti, lai atrisinātu sarežģītas, daudzpakāpju problēmas — matemātiku, loģiku, kompleksu analīzi. Lai to paveiktu, tiem ir jāveido gari, izteikti iekšēji spriešanas ķēdes. Un jo garāka ir šī ķēde, jo vairāk punktu ir, kuros modelis var novirzīties no faktiem, uzkrājot nelielas neprecizitātes, kas kumulatīvi rada kļūdainu secinājumu.
Turklāt jaunie modeļi ir programmēti atbildēt uz plašāku jautājumu loku — tostarp tad, kad tie nav droši par atbildi. Iepriekšējās paaudzes biežāk atbildēja ar "nezinu". Jaunākie modeļi atbild — un dažreiz izdomā. Šī tendence ir apzināts dizaina lēmums, nevis kļūda: lietotāji vispār ir neapmierināti ar atteikumiem atbildēt. Rezultāts ir modeli, kas ir sabiedriski lietojamāki, bet faktiski mazāk uzticami noteiktos scenārijos.
Vēl viens faktors ir interneta piekļuve. Modeļi, kas var meklēt tīmeklī, teorētiski var pārbaudīt faktus. Praksē tas dažkārt rada jaunu problēmu: modelis atrod daļēji pareizu informāciju un to papildina ar izdomātu saturu, radot ticamāku, bet kļūdaināku atbildi.
Skaidrs, pārredzams darbības mehānisms — kāds ir svarīgs gan uzticamos AI rīkos, gan regulētās digitālās izklaides platformās — ir tas, kas atšķir uzticamu sistēmu no tādas, kurā nav iespējams paļauties uz rezultātu. Tieši to demonstrē licencēts operators kā kazino Verde, kurā spēlētāji sagaida godīgas izmaksas, verificētus bonusu nosacījumus un pārskatāmu spēļu darbību.
Sekas dažādās nozarēs
Halucināciju problēma nav abstrakta. Jurisprudencē tiesas ASV kopš 2023. gada ir piemērojušas finansiālus sodus par AI ģenerētiem faktiskajiem kļūdiem juridiskajos dokumentos — rekordsods Kalifornijā sasniedza 10 000 dolāru, un kopumā šādi gadījumi ir saskaitīti desmitkārtīgi. Medicīnā AI halucinācijas rada īpašas bažas, jo nepareiza diagnostiskā informācija var tieši ietekmēt ārstēšanas lēmumus.
Ziņu nozarē NewsGuard dati atklāj, ka halucinācijas pieaug tieši tajos jautājumos, kur lasītāji visbiežāk meklē pārbaudītu informāciju — aktuālās ziņas, politika, veselība. Tas rada sistēmisku dezinformācijas risku, kas nav atrisināms tikai ar modeļu uzlabošanu. PHARE pētījums, kas vērtēja vairākus lielus valodas modeļus, tostarp GPT-4, Claude un Llama, vairākās zināšanu jomās, konstatēja, ka halucinācijas ne tikai saglabājas, bet potenciāli pieaug pēc biežuma.
Risinājumi, ko nozare meklē
Pētnieki un izstrādātāji eksperimentē ar vairākām pieejām halucināciju samazināšanai.
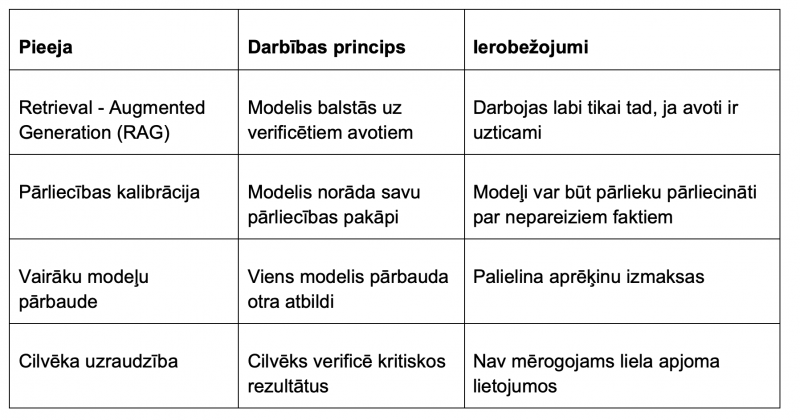
Neviens no šiem risinājumiem pagaidām nav pilnīgs. Halucināciju problēma nav tehnoloģiska kļūme, kas gaida labojumu — tā ir fundamentāla spriedze starp AI spēju radīt fluīdu, ticamu tekstu un tā nespēju garantēt šī teksta patiesumu.
Kas no tā jāzina lietotājiem
Praktiskais secinājums nav izvairīties no AI — tas ir saprast, kādos uzdevumos tas ir uzticams un kādos — nē. Halucināciju risks nav vienmērīgi sadalīts pa visiem lietojumiem; tas ir ļoti atkarīgs no uzdevuma veida.
Zems risks — uzdevumi, kuros AI ir uzticams:
- Tekstu apkopošana un pārfrāzēšana;
- Strukturēšana, formatēšana, koda rakstīšana;
- Radoša ģenerēšana, kur precizitāte nav izšķiroša;
- Darbs ar dotiem dokumentiem, no kuriem modelis var iegūt atbildi.
Augsts risks — uzdevumi, kuros nepieciešama neatkarīga pārbaude:
- Faktu verifikācija, statistika, datumi, personas;
- Medicīniska, juridiska vai finansiāla konsultācija;
- Aktuālu notikumu analīze;
- Jebkurš gadījums, kad atbildei ir reālas sekas.
Visbīstamākā situācija nav tad, kad AI atbild nepareizi — tā ir tad, kad tas atbild nepareizi ļoti pārliecinoši. Tieši tāpēc kritiskā domāšana paliek neaizstājama, neatkarīgi no tā, cik iespaidīgi izskatās modelis.